3.4 其它
3.4.1 list和dataframe/tibble
3.4.1.1 Dataframe和tibble的本质
聪明的你也许已经注意到了,dataframe/tibble抓取单列的方法和list的取子集2.4.1惊人地相似。事实上,dataframe的本质正是list,而tibble也是dataframe(只是进化了一些功能):
is.list(mpg)#> [1] TRUEclass(mpg)#> [1] "tbl_df" "tbl" "data.frame"3.4.1.2 Dataframe/tibble的取子集
Dataframe/tibble既有list的特征,也有matrix的特征。
当使用一个参数取子集的时候,比如mpg[[3]],mpg[["displ"]]或mpg$displ,tibble表现得像list,其中每一列是一个有命名的list element;
当使用两个参数取子集的时候,比如mpg[3,4], mpg[3, ], mpg[ ,4],tibble表现得像matrix
mpg[3, ]#> # A tibble: 1 x 11
#> manufacturer model displ year cyl trans drv cty hwy fl class
#> <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
#> 1 audi a4 2 2008 4 manua… f 20 31 p comp…3.4.2 Tidyverse tibble相对于Base R dataframe的优势
你可以把mpg转换成dataframe,命名为mpg1,探索两者的区别。
mpg1 <- as.data.frame(mpg)3.4.2.1 信息的显示
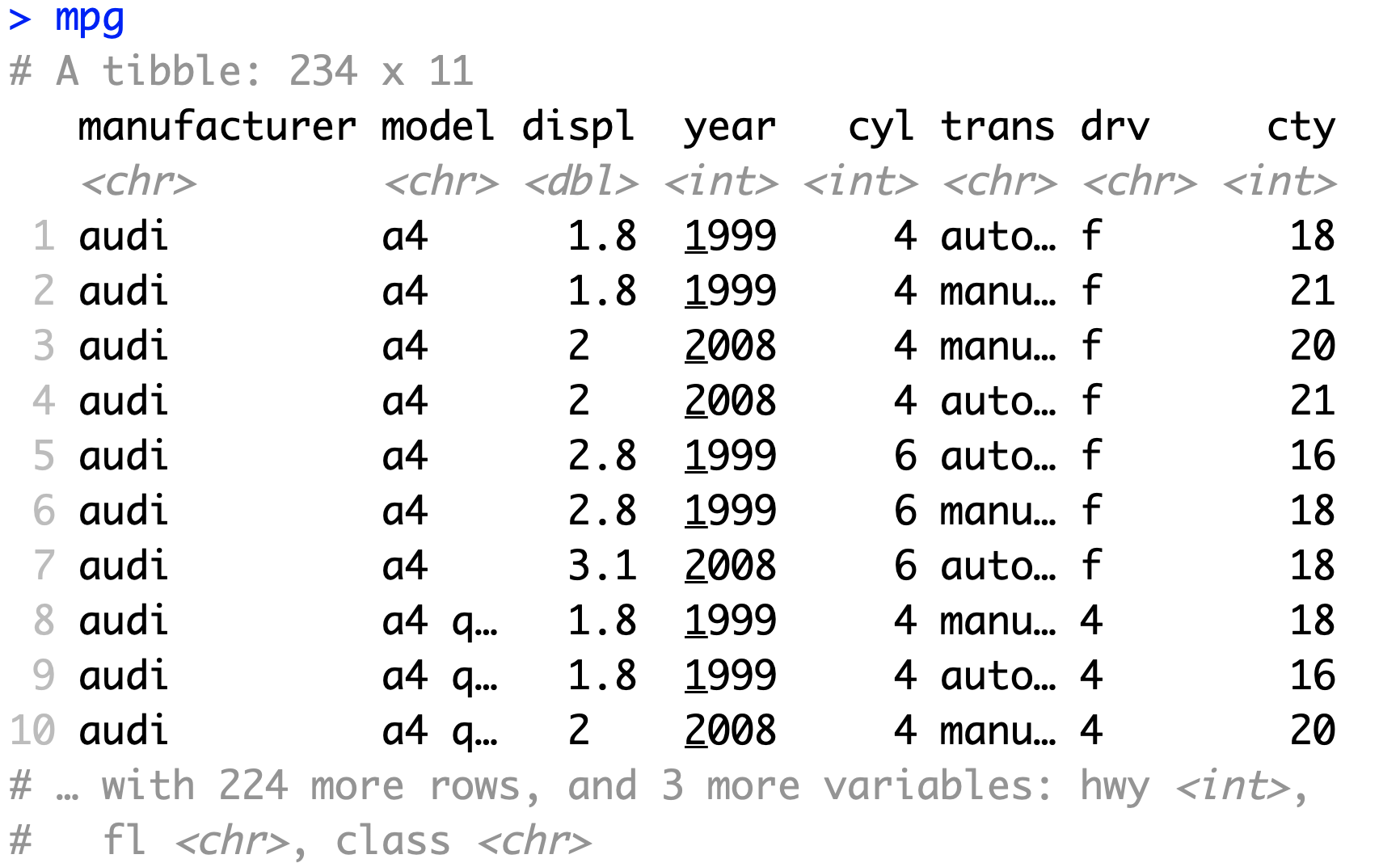
首先,查看print()结果(直接输入mpg1或者print(mpg1))
对于行数/列数较多的数据,dataframe的显示结果很乱,而且信息量小。当行数较多时,你需要往上划才能看见变量名;当你的console比较窄或者变量名太多时,dataframe会先显示一部分变量(列),再把剩余的变量(列)显示在后面。这时你需要往上划查看一部分变量,再往上划查看另一部分变量。

tibble的显示结果一致性强,信息量大。它永远只显示前10行,因此不用往上划就能看到显示的所有信息。它指明了行数和列数,变量的数据类型;当变量较多时,不会影响显示,而是在末尾指明其余的变量名字和数据类型。
3.4.2.2 tibble不会自作主张地化简结果
Base R dataframe自带的取子集函数在一些情况下不会化简结果,而在另一些情况下会自动化简结果27,这经常会造成意想不到而且很难察觉的错误,尤其对于开发者来说简直是噩梦(Gentleman 2009, 33; Wickham 2019)。对tibble取子集,永远会返回一个tibble;这样可以提高代码的一致性,降低发生错误的可能性。
请查看Advanced R了解更多。
3.4.2.3 tibble与其它tidyverse中的功能兼容性更强
很多tidyverse中的神器,如group_by,只能在tibble上使用。
References
Gentleman, Robert. 2009. R Programming for Bioinformatics. Book. Boca Raton, FL: CRC Press.
Wickham, Hadley. 2019. Advanced R. 2nd ed. CRC Press.
当选取单个数值或者单列数值的子集时,会返回一个vector,而在其他情况下会返回一个dataframe;试试
mpg1 <- as.data.frame(mpg); mpg1[2,3]; mpg1[3:5, 4]; mpg1[3, 4:6].↩