5.6 小测
描绘中华民族的伟大复兴和日、美、英、法等国的走衰。
从世界银行的网站,我们可以获取到1960年至2018年各国的GDP数据。为了一致性,请使用我做的一份拷贝 (https://github.com/TianyiShi2001/r-and-tidyverse-book-ans/tree/master/data/GDP/wb )。
用这些数据,绘制下面这张面积图:
knitr::include_graphics("img/wrangle/gdp.png")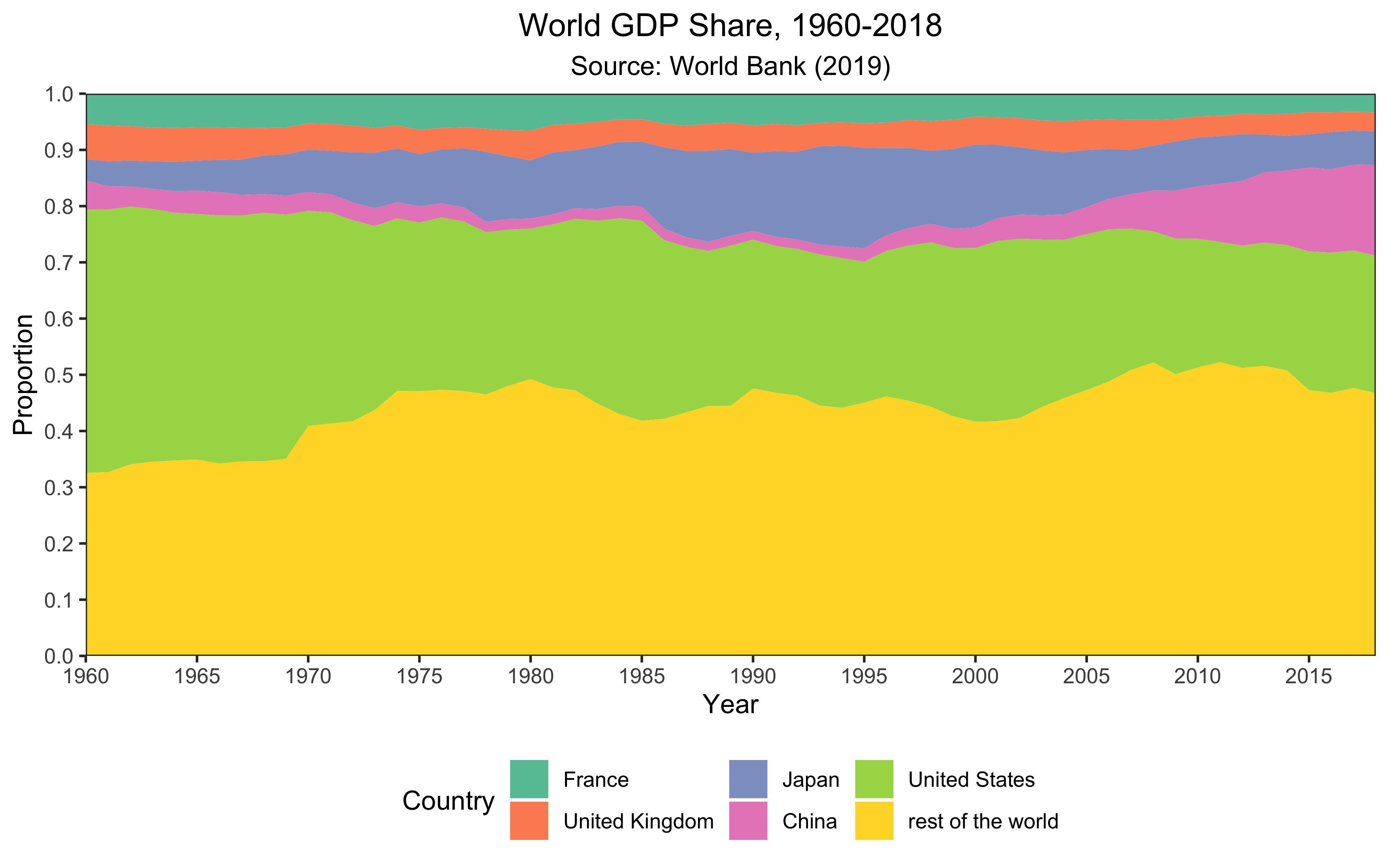
可以无视好看的颜色,标题,坐标轴,国家的排列顺序和其他的小细节。
从网页链接中提取信息。
searches <- c( "https://www.bing.com/search?q=aspirin&go=Submit&qs=ds&form=QBLH", "https://www.bing.com/search?q=bacillus+thuringiensis&qs=LS&pq=bacillus+th&sc=8-11&cvid=851739CD82A24226B0AF73E8331008EE&FORM=QBRE&sp=1", "https://www.bing.com/search?q=the+unexamined+life+is+not+worth+living&go=Search&qs=n&form=QBRE&sp=-1&ghc=2&pq=the+unexam&sc=8-10&sk=&cvid=37894978539F4E9EAA213581D6F185AE", "https://www.bing.com/search?q=heinz+wilhelm+guderian&qs=AS&pq=heinz+wilh&sk=SC1&sc=4-10&cvid=7C5F3F5769384F70BC0369316EFC51FA&FORM=QBRE&sp=2&ghc=1" )把这些必应搜索的链接的搜索内容抓取出来(你可以在浏览器里打开这些链接,看看搜索框里的内容是什么):
进而选择合适的函数把搜索内容做成一个字符向量:
#> [1] "aspirin" #> [2] "bacillus thuringiensis" #> [3] "the unexamined life is not worth living" #> [4] "heinz wilhelm guderian"